【Python】JupyterLabでmatplotlib.pyplotを実行するとクラッシュする【anaconda】
目次
JupyterLabでmatplotlibの使うと、「Pythonは動作を停止しました」と表示されクラッシュする
Anaconda Promptからコマンド「conda install freetype=2.10.4」を実行し、 2021年10月27日以降にanacondaからmatplotlibをインストール、またはアップグレードした際にインストールされるfreetype2.11.0が不具合を発生させているらしい
問題点

~開発環境~
python=3.7.11
matplotlib=3.4.3
freetype=2.11.0(matplotlibをインストールした際に勝手にインストールされる)
解決方法
「freetype」のバージョンを2.11.0から2.10.4にダウングレードする
結果

クラッシュせずに描写できた
原因
参考サイト:
stackoverflow.com
【Python】複数のフォルダから違うファイル名のデータを削除する【Google Colab】
やりたいこと
複数のフォルダから、共通していないファイル名のデータを削除したい
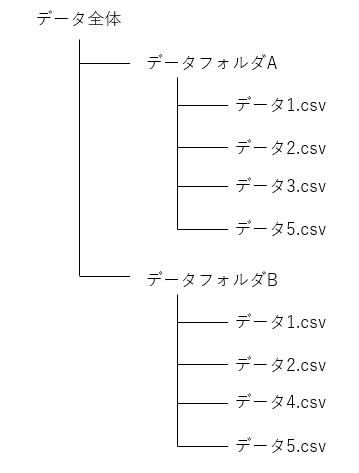
データ3.csv, データ4.csvを削除したい
作成したコード全体
import os import glob from natsort import natsorted ###エラーデータを取り除く def sort_file(files1,files2,files3,files4): i=0 while True: # どれかのファイルが最後の要素になったらwhile文を終了 if len(files1) < i+1: files2 = files2[:i] files3 = files3[:i] files4 = files4[:i] break if len(files2) < i+1: files1 = files1[:i] files3 = files3[:i] files4 = files4[:i] break if len(files3) < i+1: files1 = files1[:i] files2 = files2[:i] files4 = files4[:i] break if len(files4) < i+1: files1 = files1[:i] files2 = files2[:i] files3 = files3[:i] break # ファイルパスからファイル名を取得 file1 = os.path.splitext(os.path.basename(files1[i]))[0] file2 = os.path.splitext(os.path.basename(files2[i]))[0] file3 = os.path.splitext(os.path.basename(files3[i]))[0] file4 = os.path.splitext(os.path.basename(files4[i]))[0] # 日時の部分(10桁目)までをintで取得 file1_sliced = int(file1[:10]) file2_sliced = int(file2[:10]) file3_sliced = int(file3[:10]) file4_sliced = int(file4[:10]) # 同じ日時のデータが揃っているなら次を読み込み、揃っていないなら削除 if file1_sliced == file2_sliced == file3_sliced == file4_sliced: # 揃っているなら次の要素 i = i+1 continue # 最大値より小さいなら削除 file_max = max(file1_sliced, file2_sliced, file3_sliced, file4_sliced) # 最大値 if file1_sliced < file_max: del files1[i] if file2_sliced < file_max: del files2[i] if file3_sliced < file_max: del files3[i] if file4_sliced < file_max: del files4[i] return files1, files2, files3, files4 ###データのあるフォルダの指定 folder_path12 = 'フォルダのパス' folder_path3 = 'フォルダのパス' folder_path4 = 'フォルダのパス' folder_path5 = 'フォルダのパス' ###指定したフォルダ内のファイルのパスを取得 files12 = natsorted(glob.glob("{}/*".format(folder_path12))) files3 = natsorted(glob.glob("{}/*".format(folder_path3))) files4 = natsorted(glob.glob("{}/*".format(folder_path4))) files5 = natsorted(glob.glob("{}/*".format(folder_path5))) files12,files3,files4,files5 = sort_file(files12,files3,files4,files5)
上記のコードは、ファイル名の最初10桁目までに日時情報が入っているデータを扱っており、4つのフォルダ(files12, files3, files4, files5)すべてに共通するデータのファイルパスが返される
【Python】glob.globで読み込んだファイルの順番がバラバラ【Google Colab】
問題点
import glob file_paths = glob.glob("データのあるフォルダのパス")
で読み込むと、順番がバラバラで読み込まれている
例えば、data1~data5のように名前に数字が入っているファイルから構成されたフォルダを参照すると
data2,
data4,
data5,
data1,
data3
という順番で読み込まれてしまう
解決方法
natsortedで並び替え
修正後のコード
import glob from natsort import natsorted file_paths = natsorted(glob.glob("データのあるフォルダのパス"))
これで data1, data2, data3, data4, data5 という順番で読み込まれる
【Python】csvファイルを読み込んで、npyファイルで保存する【Google Colaboratory】
なぜnpyファイルに変換するのか
機械学習を行う際に、自分で計測した結果が記録してあるcsvデータを読み込むことが必要となった
データ数が増えるとcsvファイルの読み込みに時間がかかるので、学習モデルを変更する度に大量のデータを読み込む時間が鬱陶しくなる
npyファイルの読み込みは処理が速いので、一度csvファイルを読み込んでnpyファイルとして保存し、次からはnpyファイルを読み込む
結果
テストとして自作データ(28データ)を読み込む際の読み込み時間を比較する
csvファイルの読み込み時間:243.9秒
npyファイルの読み込み時間:24.4秒
後で見直す際にコード全文をすぐ見たいので先にコード全文を載せておきます
~コード全文~
from google.colab import drive drive.mount('/content/gdrive',force_remount=True) import numpy as np import os import glob #末尾から0を取り除く def trim_zeros(arr): """Returns a trimmed view of an n-D array excluding any outer regions which contain only zeros. """ slices = tuple(slice(idx.min(), idx.max() + 1) for idx in np.nonzero(arr)) return arr[slices] def save_npy(files,save_folder_path): i=0 for file in files: X_data = np.loadtxt(file, # 読み込みたいファイルのパス delimiter=",", # ファイルの区切り文字 skiprows=0, # 先頭の何行を無視するか(指定した行数までは読み込まない) usecols=(0,1), # 読み込みたい列番号 ndmin = 2 # 返される配列の次元数の指定 ) y_data = np.loadtxt(file, # 読み込みたいファイルのパス delimiter=",", # ファイルの区切り文字 skiprows=0, # 先頭の何行を無視するか(指定した行数までは読み込まない) usecols=(9) # 読み込みたい列番号 ) #末尾から0を取り除く(trim_zeros()) X_data = trim_zeros(X_data) y_data = trim_zeros(y_data) min_size = min(len(X_data),len(y_data)) X_data = X_data[:min_size,:] y_data = y_data[:min_size] # ディレクトリがなければ作成 os.makedirs(save_folder_path + '/X_data', exist_ok=True) os.makedirs(save_folder_path + '/y_data', exist_ok=True) #拡張子npyで保存 np.save(save_folder_path + '/X_data' + '/X_data{}'.format(i), X_data) np.save(save_folder_path + '/y_data' + '/y_data{}'.format(i), y_data) print('read_files {}/{} data finished'.format(i+1,len(files))) i = i+1 #データファイル名読み込み folder_path = './gdrive/My Drive/Colab Notebooks/EMG_estimation/EMG_data' files = glob.glob("{}/*".format(folder_path)) #保存するフォルダ名 save_folder_path = './gdrive/My Drive/Colab Notebooks/EMG_estimation/EMG_data_npy' save_npy(files,save_folder_path)
~モジュールのimportなど~
#Googleドライブのマウント from google.colab import drive drive.mount('/content/gdrive',force_remount=True) import numpy as np import os import glob
初めの3行はGoogleドライブ内のファイルを参照する際に必要となる
実行して出てきたURLからアカウントを選択して許可を押すとコードが出てくるので、コピーして「Enter your authorization code:」にペーストする
~ファイル名(.csv)の読み込み~
#データファイル名読み込み folder_path = './gdrive/My Drive/Colab Notebooks/EMG_estimation/EMG_data' files = glob.glob("{}/*".format(folder_path))
関数glob()によってフォルダー内のすべてのファイルを読み込むことが可能
~データ末尾の0を取り除く~
#末尾から0を取り除く def trim_zeros(arr): """Returns a trimmed view of an n-D array excluding any outer regions which contain only zeros. """ slices = tuple(slice(idx.min(), idx.max() + 1) for idx in np.nonzero(arr)) return arr[slices]
自分の扱うデータは、データの末尾が0で埋められているので取り除く関数を定義しておきます
※これは各々のデータに合わせて削除してもらってもかまいません
~データ(.csv)の読み込み~
X_data = np.loadtxt(file, # 読み込みたいファイルのパス delimiter=",", # ファイルの区切り文字 skiprows=0, # 先頭の何行を無視するか(指定した行数までは読み込まない) usecols=(0,1), # 読み込みたい列番号 ndmin = 2 # 返される配列の次元数の指定 ) y_data = np.loadtxt(file, # 読み込みたいファイルのパス delimiter=",", # ファイルの区切り文字 skiprows=0, # 先頭の何行を無視するか(指定した行数までは読み込まない) usecols=(9) # 読み込みたい列番号 ) #末尾から0を取り除く(trim_zeros()) X_data = trim_zeros(X_data) y_data = trim_zeros(y_data) #データのサイズを合わせる min_size = min(len(X_data),len(y_data)) X_data = X_data[:min_size,:] y_data = y_data[:min_size]
関数np.loadtxt()により、csvデータの読み込みを行う
usecolsで読み込みたい列の指定も可能
データ末尾が欠損している場合があるのでデータサイズを合わせている
~npyデータの保存~
# ディレクトリがなければ作成 os.makedirs(save_folder_path + '/X_data', exist_ok=True) os.makedirs(save_folder_path + '/y_data', exist_ok=True) #拡張子npyで保存 np.save(save_folder_path + '/X_data' , X_data) np.save(save_folder_path + '/y_data' , y_data)
関数np.save(保存するフォルダーのパス+ファイル名,保存するデータ(ndarray))で保存が出来る
【Python】多変量時系列データ畳み込みニューラルネットワーク、データ前処理部分の変更
問題点:畳み込みニューラルネットワーク学習モデルの精度が低い
解決方法:データの前処理部分のコードを変更
詳細:
被験者の運動動作時の脳波データ(データセット:BCI competition IV dataset2a)から、動かそうとした箇所(舌,右手,左手,両足の4パターン)を判定するプログラムの作成中、参考にしたプログラム(https://github.com/ahujak/EEG_BCI)との正解率と異常に離れていることに気づいた。学習モデルは同じものを生成していたので、データを読み込む部分がおかしいと睨み、コードの修正を行った。
開発環境:GoogleColaboratory
参考にしたプロジェクトはデータセットが入っていなかったので、データを読み込む部分は別の方のコードを参考に作成していた。参照するディレクトリは"./gdrive/MyDrive/data/A01T_slice.mat"(A01~A09)となっている。
修正前のコード:
import h5py import numpy as np #ファイルの読み込み def import_data(every=False): if every: electrodes = 25 else: electrodes = 22 X, y = [], [] drive_root_dir="./gdrive/My Drive/data" for i in range(9): A01T = h5py.File(drive_root_dir + "/A0" + str(i + 1) + 'T_slice.mat', 'r') X1 = np.copy(A01T['image']) X.append(X1[:, :electrodes, :]) y1 = np.copy(A01T['type']) y1 = y1[0, 0:X1.shape[0]:1] y.append(np.asarray(y1, dtype=np.int32)) for subject in range(9): delete_list = [] for trial in range(288): if np.isnan(X[subject][trial, :, :]).sum() > 0: delete_list.append(trial) X[subject] = np.delete(X[subject], delete_list, 0) y[subject] = np.delete(y[subject], delete_list) y = [y[i] - np.min(y[i]) for i in range(len(y))] return X, y #データの変換 def train_test_subject(X, y, train_all=True, standardize=True): l = np.random.permutation(len(X[0])) X_test = X[0][l[:100], :, :] y_test = y[0][l[:100]] if train_all: X_train = np.concatenate((X[0][l[100:], :, :], X[1], X[2], X[3], X[4], X[5], X[6], X[7], X[8])) y_train = np.concatenate((y[0][l[100:]], y[1], y[2], y[3], y[4], y[5], y[6], y[7], y[8])) else: X_train = X[0][l[100:], :, :] y_train = y[0][l[100:]] X_train_mean = X_train.mean(0) X_train_var = np.sqrt(X_train.var(0)) if standardize: X_train -= X_train_mean X_train /= X_train_var X_test -= X_train_mean X_test /= X_train_var X_train = np.transpose(X_train, (0, 2, 1)) X_test = np.transpose(X_test, (0, 2, 1)) return X_train, X_test, y_train, y_test X, y = import_data(every=False) X_train,X_test,y_train,y_test = train_test_subject(X, y)
修正後のコード:
import h5py from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder, OneHotEncoder import numpy as np drive_root_dir = './gdrive/My Drive/data' def load_data_from(file_num): file_name = drive_root_dir + '/A0' + str(file_num) + 'T_slice.mat' cur_data = h5py.File(file_name, 'r') X = np.copy(cur_data['image'])[:, 0:22, :] y = np.copy(cur_data['type'])[0,0:X.shape[0]:1] y = np.asarray(y) # print(X.shape) # print(y.shape) return X,y X, y = load_data_from(1) X = np.nan_to_num(X) y = LabelEncoder().fit_transform(y) y = OneHotEncoder(sparse=False).fit_transform(y.reshape(-1, 1)) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 100) for i in range(2,10): X2, y2 = load_data_from(i) X2 = np.nan_to_num(X2) y2 = LabelEncoder().fit_transform(y2) y2 = OneHotEncoder(sparse = False).fit_transform( y2.reshape(-1,1) ) X2_train, X2_test, y2_train, y2_test = train_test_split(X, y, test_size=50) X_train = np.concatenate((X_train,X2),axis=0) X_test = np.concatenate((X_test, X2_test), axis=0) y_train = np.concatenate((y_train, y2), axis=0) y_test = np.concatenate((y_test, y2_test), axis=0)
締め:
これにより、学習モデルの正解率は57%から72%になった。
やはりデータの前処理部分に問題があったみたいだが、未だに修正前のコードの悪点が分かっていないので、コメントしていただけると嬉しいです。
参考にしたコード:
学習モデル:https://github.com/ahujak/EEG_BCI
修正後のコード:https://github.com/ritabugking/ECE239AS-DeepLearning/blob/master/finalProject/cnn1.py